

|
2008| 0
|



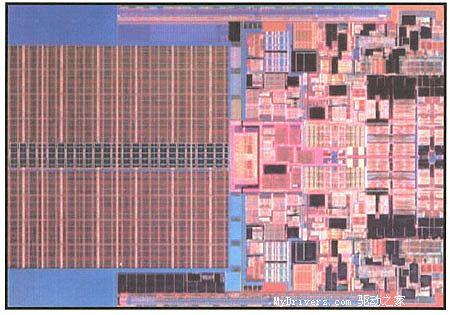
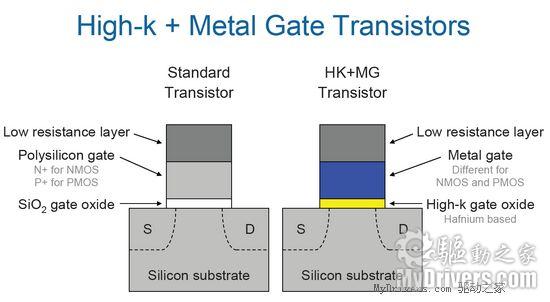
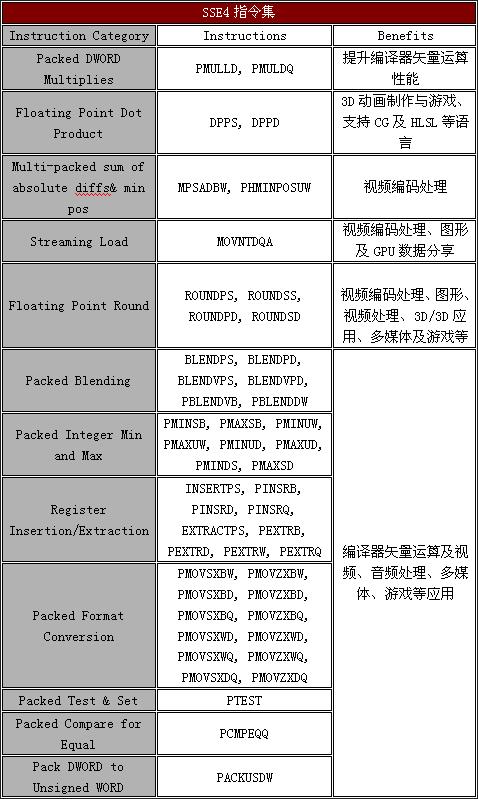
[转贴]Intel 45nm 处理器 |
|
|
|
|
相关帖子
|
||

 IP卡
IP卡 狗仔卡
狗仔卡

 发表于 2008-1-10 03:53 AM
发表于 2008-1-10 03:53 AM












 收藏
收藏 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡JBTALKS.CC |联系我们 |隐私政策 |Share
GMT+8, 2024-11-26 02:24 AM , Processed in 0.104503 second(s), 28 queries .
Powered by Discuz! X2.5
© 2001-2012 Comsenz Inc.
Domain Registration | Web Hosting | Email Hosting | Forum Hosting | ECShop Hosting | Dedicated Server | Colocation Services
Copyright © 2003-2012 JBTALKS.CC All Rights Reserved

{kind=link}